
Hello all,
Usually I can solve issues like this myself, but I seem unable to find the bug in my code this time. I think I must be misunderstanding something about the Vulkan sync model for this to happen, but am unsure what it is.
The setup
I've created a Vulkan application to play around with cluster culling. It creates a large grid mesh, with about 30M triangles, which are then clustered together in groups of 128.
It then runs a compute shader that inspects each cluster and decides to cull the cluster or not. Currently it simply accepts all clusters as visible and outputs them into a new sequential buffer. The compute shader also fills a DrawIndirect struct with the proper cluster size (vertex count) and visible cluster count (instance count).
Then with an DrawIndirect command I render the visible clusters.
The issue
While this works just fine for ‘small’ batches, I was using the Lucy model as a large scale test case and noticed issues there. For some reason, the vertex count of the DrawIndirect struct isn't being filled, and the value for the instance count is too low.
The details
Compute shader code for the cluster culling (which doesn't currently cull anything):
#version 430
#extension GL_ARB_compute_shader : enable
#define CLUSTER_SIZE 128
struct dd_mesh_cluster_data_t {
uint base_vertex;
uint base_index;
int padding_A;
int padding_B;
};
struct dd_draw_indirect_command_t {
uint vertex_count;
uint instance_count;
uint vertex_offset;
uint instance_offset;
};
layout(local_size_x = 64) in;
layout(local_size_y = 1) in;
layout(local_size_z = 1) in;
layout(push_constant) uniform Parameters {
uint cluster_count;
} params;
layout(std430, binding = 0) readonly buffer all_clusters_t {
dd_mesh_cluster_data_t all_clusters[];
};
layout(std430, binding = 1) writeonly buffer visible_clusters_t {
dd_mesh_cluster_data_t visible_clusters[];
};
layout(std430, binding = 2) volatile buffer visible_cluster_count_t {
dd_draw_indirect_command_t cluster_draw_indirect[];
};
shared uint local_count;
shared uint offset;
void main() {
// Reset the count.
if (gl_LocalInvocationID.x == 0) {
cluster_draw_indirect[0].vertex_count = 0;
cluster_draw_indirect[1].vertex_count = 0;
local_count = 0;
}
memoryBarrierBuffer();
memoryBarrierShared();
memoryBarrier();
barrier();
const uint id = gl_GlobalInvocationID.x;
const bool keep_cluster = ((id < params.cluster_count));
uint output_cluster_index = 0;
if (keep_cluster) {
output_cluster_index = atomicAdd(local_count, 1);
}
memoryBarrierBuffer();
memoryBarrierShared();
memoryBarrier();
barrier();
if (gl_LocalInvocationID.x == 0) {
offset = atomicAdd(cluster_draw_indirect[1].vertex_count, local_count);
}
memoryBarrierBuffer();
memoryBarrierShared();
memoryBarrier();
barrier();
if (gl_LocalInvocationID.x == 0) {
visible_clusters[gl_WorkGroupID.x].padding_A = int(gl_WorkGroupID.x);
visible_clusters[gl_WorkGroupID.x].padding_B = int(local_count);
}
if (keep_cluster) {
output_cluster_index += offset;
visible_clusters[output_cluster_index].base_vertex = all_clusters[id].base_vertex;
visible_clusters[output_cluster_index].base_index = all_clusters[id].base_index;
}
memoryBarrierBuffer();
memoryBarrierShared();
memoryBarrier();
barrier();
if (gl_GlobalInvocationID.x == 0) {
uint visible_clusters = cluster_draw_indirect[1].vertex_count;
// It appears the following lines isn't executed when cluster count is large.
cluster_draw_indirect[0].vertex_count = CLUSTER_SIZE * 3;
cluster_draw_indirect[0].instance_count = visible_clusters;
cluster_draw_indirect[0].vertex_offset = 0;
cluster_draw_indirect[0].instance_offset = 0;
}
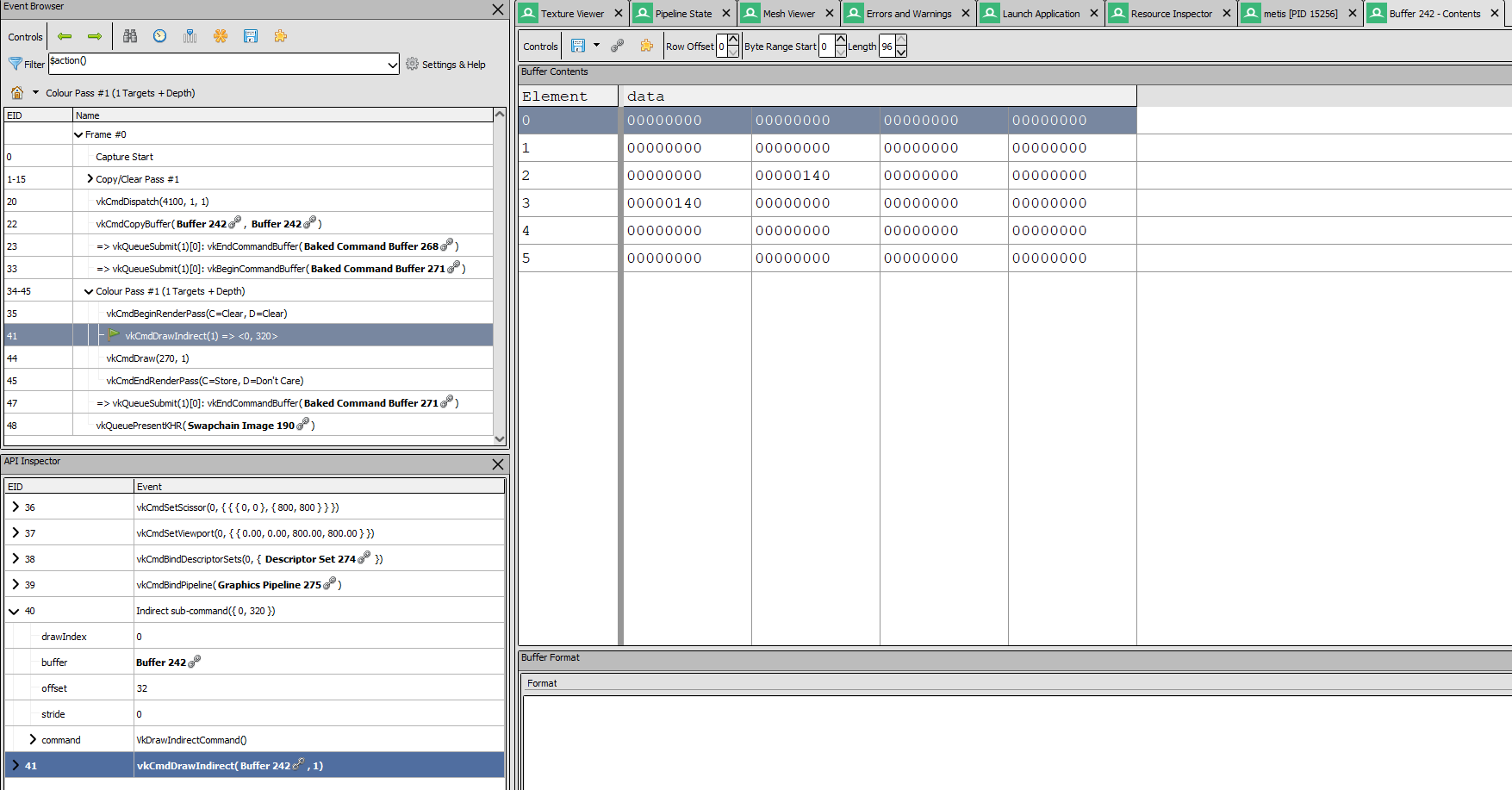
}This is a screenshot of a RenderDoc capture of the issue.
- You can see compute dispatch with 4100 workgroups (= 262369 clusters / 64 work group size)
- Not visible here, but there is a PushConstant setting the cluster count correctly to 262369.
- The DrawIndirect struct is in element 2 of Buffer 242 which is visible on the right
- Visible cluster count is also in the first data element of element 3 of Buffer 242 (this was a test)
- Visible cluster count is output as 0x140, which is 320 clusters (incorrect)
- DrawIndirect is called with instance count of 320 (incorrect, but matches data), and vertex count 0 (incorrect, but matches data)
- Although the compute shader should be filling the DrawIndirect struct, I've also saved the value elater in the buffer, and I do a CopyBuffer to put it in the right place. This step shouldn't be needed but I've been trying all kinds of things to get this to work stable.
- You can't see it in the screen shot, after the Dispatch, but before the CopyBuffer is a PipelineBarrier(, VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,…). As I understand it this should ensure all the invocations of the shader are finished before continuing with the next command.
What to solve?
At the very least I expect the shader to write 128 * 3 = 378 into the vertex count element of the DrawIndirect struct, as there is always a shader invocation with gl_GlobalInvocationID.x==0. Why this isn't happening is beyond me, and seems to indicate a sync issue (maybe my barrier is wrong).
I'm willing to share the program and or captures (quite big) if they will help, but maybe someone can already point me in the right direction with this info.




